
はじめに
Difyで生成AIアプリを作成する際は、まず 「どのAIモデルを採用するか」 を決める必要があります。設定項目は大きく分けて5つあり、下記の3つが必須、残り2つが 必要に応じて追加する形です。
| 区分 | モデルの種類 | 役割(Dify/生成 AI に不慣れな方向けの補足) |
|---|---|---|
| 必須 | ① システム推論モデル | アプリの「頭脳」。ユーザーからの質問を理解し、回答を生成する大規模言語モデル(LLM)です。 |
| ② 埋め込みモデル | テキストを数値ベクトルに変換し、類似検索や検索拡張生成(RAG)を行うためのモデルです。 | |
| ③ Rerank(リランキング)モデル | 検索で得られた複数候補を文脈に合う順に並べ替え、より的確な回答を導きます。 | |
| 任意 | ④ 音声 → テキスト(STT)モデル | 音声データをテキストに変換します。 |
| ⑤ テキスト → 音声(TTS)モデル | 生成したテキストを音声で読み上げます。 |
モデル設定の手順(3 ステップ)
- モデルプロバイダーを選ぶ
例:OpenAI・Anthropic・Amazon Bedrockなど。提供するモデル、料金体系や日本語性能が異なるため、用途と予算を見比べて選択します。 - プロバイダーが提供するモデルを有効化/無効化する
「モデルプロバイダー」設定ページで、上表の5種に設定する可能性があるモデルをオン/オフ切り替えます。筆者は 「うっかり使うとデポジット(前払い残高)を一気に消費してしまう高額モデル」 も、あらかじめ オフ にしています。 - デフォルトで使用するモデルを指定する
有効化したモデルの中から、「システム推論モデル」などアプリが既定で呼び出すモデルを選びます。ここで決めたモデルが、ユーザーが特に変更しない限り使われます。
①モデルプロバイダーを選ぶ
筆者は 生成AI業界の定番モデルを中心に利用しています。業務で比較検証する際に Google Gemini や オンプレミスで動かすローカルLLMなども試しますが、最終的には下記の構成に落ち着くケースがほとんどです。
| 用途 | 採用モデル | 選択理由・特徴 |
|---|---|---|
| システム推論 | OpenAI GPT シリーズ / Anthropic Claude シリーズ | GPT: 精度が高く、特定用途に強いモデルの種類も豊富。短〜中コンテキストでの指示追従度が高い。 Claude: 要約や法務レビューなど長文タスクに強い。日本語が自然で丁寧な回答。上位モデルはPDFを直接インプット可能。 |
| 埋め込み | OpenAI text-embedding シリーズ | 多言語で高い語義分解能力を持ち、RAG用途のベンチマークで優れる。価格性能比が良い。 |
| Rerank | Cohere Reranker | OpenAI / Google 提供の Rerank ベンチを上回る精度指標(NDCG・MAP)を記録。API レイテンシが短く、検索→再順位付けの遅延を最小化。 |
| 音声→テキスト(STT) | OpenAI Whisper | 騒音下でも高精度(Word Error Rate 5% 前後)。モデルサイズが複数。 |
| テキスト→音声(TTS) | OpenAI TTS | 表情豊かな音声プリセットが多彩(ニュース調・カジュアル等)。速度・音程の細かいパラメータ制御が可能。 |
上表のように、モデルプロバイダーはOpenAI、Anthropic、Cohereの3社で用途をカバーできるため、筆者はこの3つに絞って設定しています。もっとも、OpenAI のモデルは Microsoft Azure版でも利用できますし、Google Geminiなど他社のモデルも非常に高性能です。ですから、筆者の選択が “唯一の正解” というわけではありません。
ポイント
- モデル間の細かな違いを理解し、自分で最適解したい方 は、用途に合わせて自由に組み合わせてOK。
- 「違いがよく分からないので、まずは無難な構成で始めたい」という方 は、今回挙げた3社の組み合わせでスタートすると失敗が少ないと思います。
ところで、当ブログは プロのAI エンジニア向けというよりも、
- 業務寄りのIT部門やDX 推進担当者といったプロ AI ユーザー
- 個人で生成 AI を気軽に試してみたいカジュアル層
を主な読者として想定し、「分かりやすく・手間をかけず・低コスト」 を軸に情報を発信しています。
モデルや開発環境の選択でもこの方針を採用しています。たとえば企業ユースでは、信頼性を重視して 本家よりもMicrosoft Azure版 OpenAIを採用するケースが多いのですが、AzureはAPIキー発行までの手順が本家より煩雑です。そこで本記事では、本家OpenAIやCohereといった、よりシンプルに始められる選択肢を紹介しています。
プロのAIエンジニアの皆さまへ
既に十分ご存じの内容が多いかもしれませんが、もし興味をお持ちいただければ大歓迎です。専門家の視点からのフィードバックも、ぜひお聞かせください。
②プロバイダーが提供するモデルを有効化/無効化する
有効化しているOpenAIモデルと無効化の基準
筆者が現在オンにしているのは、
- 安価で高性能
- 上位互換がまだ出ていない
モデルだけです。反対に、次のいずれかに当てはまるモデルはオフにしています。
| オフにする理由 | 例 |
|---|---|
| すでに上位互換モデルがあり、コストと性能のバランスで劣る | 旧世代の GPT-4x モデル など |
| 料金が割高で、少し使うだけでもデポジットを圧迫する | o1モデルなど |
| 推論速度が遅く、ユーザー体験を損なう | 超高精度だがレイテンシが高いモデル |
モデル名に「日付がある/ない」の違い
| 表記 | 意味 | こんなときに便利 |
|---|---|---|
gpt-4.1 | 同系統(gpt-4.1)の 最新バージョンを常に指すエイリアス。OpenAI がアップグレードすると自動で切り替わります。 | 「とにかく最新版を使いたい」「細かいバージョン管理は不要」 |
gpt-4.1-YYYY-MM-DD例: gpt-4.1-2025-04-14 | 発行日に固定されたバージョン。新しいリリースがあっても内容は変わりません。 | アップデートで挙動が変わると困る検証・運用シナリオ |
上記を目安に、プロジェクトの目的や運用要件に合わせてモデルを選んでみてください。筆者は下記のモデルをオンにしています。
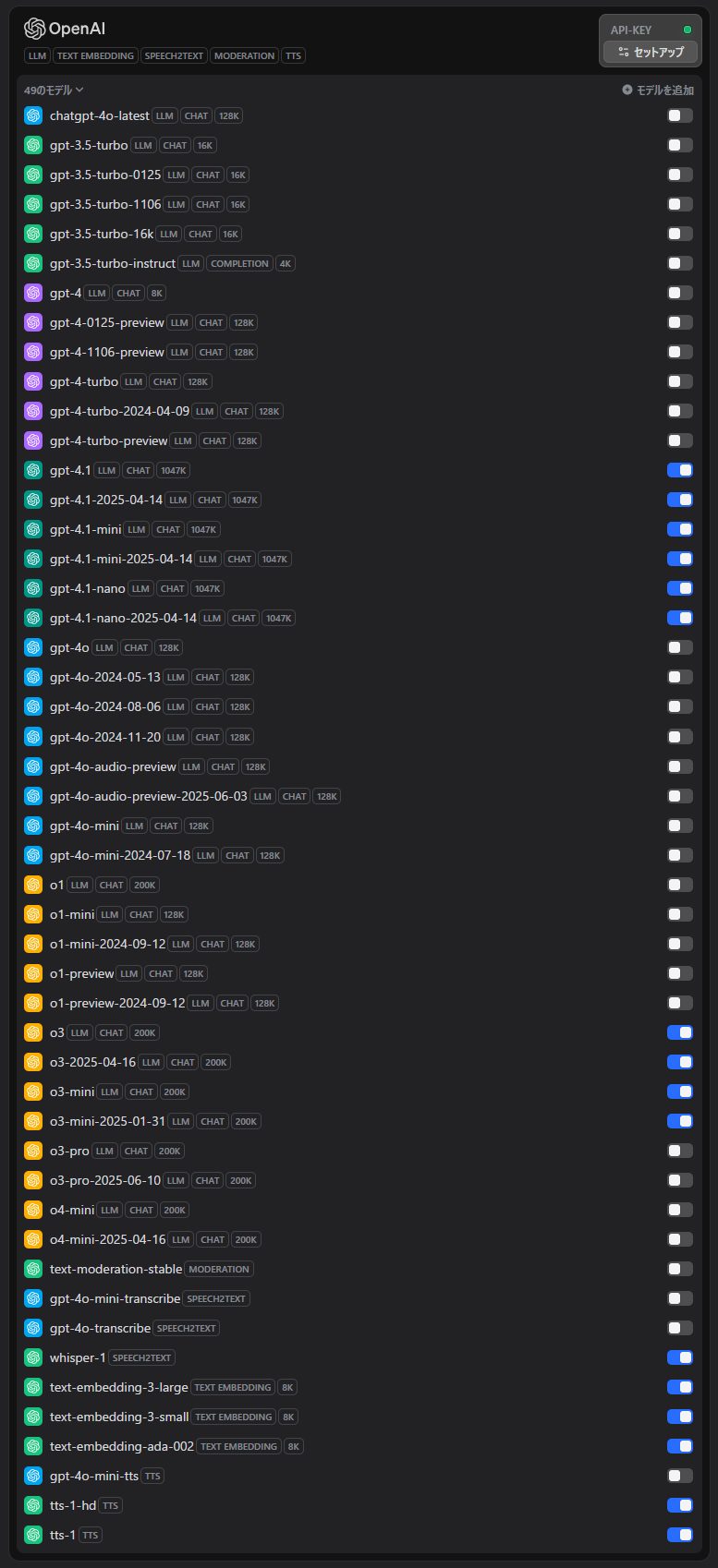
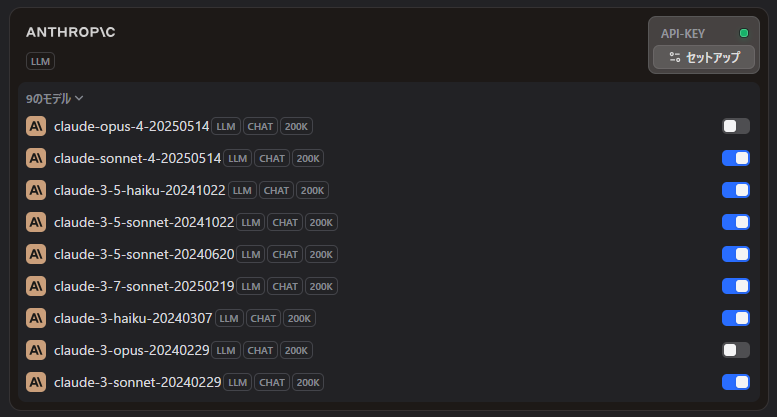
有効化しているAnthropicモデル
Anthropicでオンにしているモデルです。高価なopusモデルのみオフにしています。
有効化しているCohereモデル
Cohereはrerank-v3.5のみオンにしています。v3.0では英語版と多言語版が分かれていましたが、v3.5では統一されています。
③デフォルトで使用するモデルを指定する
②で有効化したモデルの中から、システムが既定で使用するデフォルトモデルを選択します。モデルは各処理の設定で切り替え可能であり、ここで決めるのは「特に指定がない場合に自動で使われる初期値」となります。
筆者は下記のようにデフォルトモデルを設定しています。
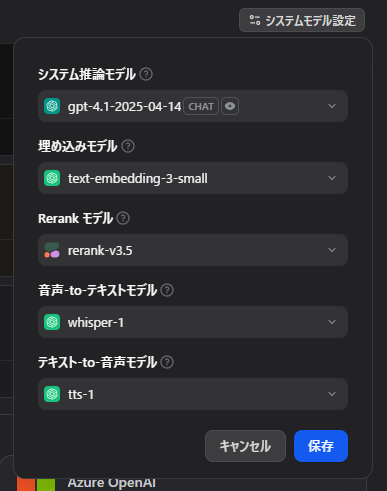
これでDifyの基本設定は整いました。次回はいよいよ、サンプルアプリを実際に作ってみたいと思います。


コメント